
Data Science products and projects typically follow a similar process, consisting to my experience of the following key steps:
- Formulate a Research Question
- Data Collection
- Data Exploration/Analysis
- Data Cleaning and Preparation
- Model Prediction
- Validation
- Visualization
- Post-Processing
Incorporating Test-Driven Development (TDD) into Data Science projects can dramatically improve code quality, ensure a well-architected pipeline, and facilitate maintenance and further development. TDD helps by ensuring that each part of the pipeline works as expected, allowing for smooth iterations and continuous improvement. On average 45 percent of the errors can be detected and resolved when using TDD1.
A common data pipeline in data science looks as follows:

«Clean code that works, in Ron Jeffries‘ pithy phrase, is the goal of Test-Driven Development (TDD).»
Kent Beck: Test Driven Development by Example.
Let’s have a look at the different processing steps and how the pipeline could be structures using Teat-Driven Design.
1. Starting with the Research Question
Before jumping into development, it’s crucial to start with a well-defined research question. Ask yourself and your team:
- What is the goal of this analysis or model?
- Why is this goal important, and how does it align with the business or research objectives?
- How will we measure success? What metrics matter to the customer or stakeholders?
Defining these early helps set the foundation for building a pipeline that’s both purpose-driven and testable.
3. Data Exploration: Laying the Foundation
Exploratory Data Analysis (EDA) is crucial for building a solid pipeline. It helps you quickly understand the data’s structure, spot patterns, and identify issues like missing values or outliers. The goal is to gather just enough insights to guide pipeline development—overanalyzing often brings diminishing returns. EDA provides the necessary inputs to make informed decisions without delaying the process.
3. TDD in Data Science Pipelines
Having the research questions for providing direction and the EDA for understanding the input data, one can start with building a pipeline. Data Science pipelines often require two distinct types of tests: unit tests and validation tests. TDD provides a systematic approach for handling both.
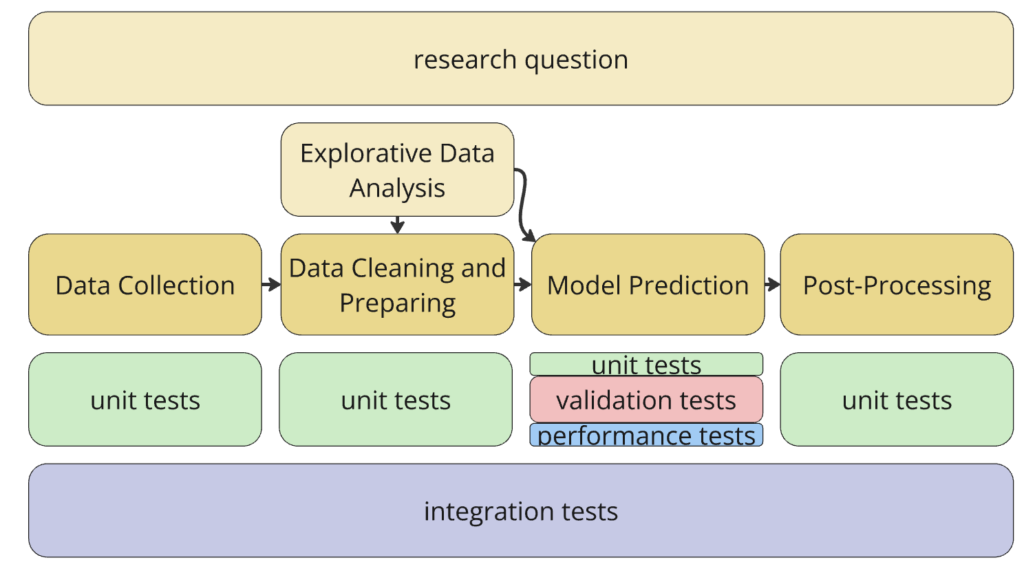
Unit Tests
For many stages in the pipeline, unit tests can be applied to ensure components are functioning as expected:
- Data Collection: Test that the data is being collected from the right sources in the correct format.
- Data Cleaning and Preparation: After exploring the data, write tests to confirm that the cleaning logic is correct and that data integrity is maintained as new transformations are applied. For example, if you’re filling missing values or standardizing formats, unit tests can ensure these transformations are consistent over time.
- Model Prediction: While predictions themselves can’t be tested as “right” or “wrong” with certainty, you can write unit tests for individual model components. For instance, you can test the data inputs, model behavior (e.g., ensuring the model accepts the correct input shapes), or specific parts of your model pipeline (such as feature generation or encoding steps).
- Post-Processing: Test final data transformations and ensure correct format.
Validation Tests: Handling Uncertainty
However, Data Science pipelines also involve an element of uncertainty, especially when it comes to model predictions. In many cases, the outcome is inherently unknown—predictions are estimates of future events, and their accuracy may only become apparent in the future or even never, due to evolving conditions. Here’s where validation tests become crucial. For stages where outcomes are uncertain, such as model predictions, you can approach testing differently:
- Model Validation with Known Data: Use historical data where outcomes are already known to test the model’s accuracy. Instead of expecting perfect predictions, evaluate the model using performance metrics such as:
- Mean Squared Error (MSE)
- Precision, Recall, F1 Score (for classification problems)
- R-squared (for regression tasks) These metrics give you an estimate of the model’s performance and can be tracked over time to ensure the model remains effective.
- Automated Validation Pipelines: Set up automated processes that run validation on a sample of new data as it becomes available, checking that the model performance remains within acceptable limits.
- Backtesting and Simulation: For certain types of models (e.g., time series or financial models), you can simulate past data and backtest predictions to measure accuracy retrospectively.
- Customer Feedback as Validation: If objective validation isn’t always possible (e.g., in cases where no clear ground truth exists), gathering feedback from users or stakeholders is another way to measure success. A feedback loop helps align the model’s predictions with business value and real-world usefulness.
4. Integration Tests: Ensuring Cohesion
In addition to unit and validation tests, integration tests are essential to verify that all components of the data pipeline work seamlessly together. These tests ensure that data flows correctly through each stage, from collection to final predictions, and that intermediate transformations function as expected. At the end of development, running end-to-end tests on the entire pipeline guarantees that the system behaves as a cohesive unit, catching any issues that may arise from component interactions.
5. Visualisation: Presenting Results Effectively
Creating clear, insightful visualizations is key to demonstrating the value of your analysis to customers. Well-designed plots help convey complex results in an accessible way, making it easier to highlight trends, outliers, and key findings. These visualizations not only serve as proof that the results meet expectations but also provide a solid foundation for discussions and decisions. By presenting data in a compelling format, you ensure that stakeholders can confidently interpret and act on the insights.
6. Iterating on the Model
TDD in Data Science allows you to take an iterative approach to refining your models. While unit tests ensure that the components of your pipeline are working correctly, validation tests and performance metrics allow you to continuously improve and adapt your models as more data becomes available or as conditions change.
Incorporating TDD into your data science workflow helps strike a balance between maintaining control over known processes (e.g., data cleaning, pipeline integrity) and handling the inherent uncertainty of predictions. As a result, you build more reliable, scalable, and maintainable data science products.
- Capers Jones: Software Engineering Best Practices. Lessons from Successful Projects in the Top Companies. Mc Graw Hill, 2010, ISBN 978-0-07-162162-5, S. 660 (englisch, 960 S.). ↩︎